HHdbVI: PGN
(This post has been updated since its first appearance, once it was discovered that the HHdbVI.pgn file is not really UTF-8 encoded, even though it contains an UTF-8 BOM.)
As I’ve already mentioned in another post, I’m trying to extract relevant information from the Harold van der Heijden’s study database (see http://www.hhdbvi.nl/) and put it into a form that I can import into my own database. (That format is basically the same as the PBI format. )
In that post, I focussed on finding the best = earliest version of the PGN standard in order to implement to PGN-reading software for the job.
The present post looks at issues that relate to the basic PGN format. Future posts will deal with extracting names and source and tourney information from the HHdbVI data.
Issue 1: Character encoding
(This issue was found in files downloaded on 2020-12-06 – I see no obvious version or release information in the downloaded material. On 2021-01-11 it was reported as a probable database bug to H. van der Heijden.)
PGN stipulates ISO 8859-1 as character encoding (section 4.1 of the PGN Standard). It also assumes the presence of a number of control characters (not part of ISO 8869-1 which only specifies graphic/printable characters, but 7-bit ASCII control characters can probably be assumed safely.)
The file HHdbVI.pgn starts with a Unicode BOM (Byte-Order Mark) which is standard indication that the file is encoded as UTF-8.
On a Unix/Linux computer, this can be tested by the following command:
$ file HHdbVI.pgn
HHdbVI.pgn: UTF-8 Unicode (with BOM) text, with CRLF line terminators
This goes against the PGN standard. While there seem to be several chess applications that accept this file, and presumably allow Unicode encoding, there are also several that don’t. There appears to be no proposed standard or extension to the standard that covers this encoding. It is possible to guess, of course, but the whole purpose of a standard is to reduce the need for guessing to a minimum.
But … it also appears to be incorrect. While a UTF-8 BOM indubitably is present, the rest of the file does not appear to be UTF-8 encoded at all. (This should cause errors/warnings in any application that knows UTF-8.)
This became apparent as the HHdbVI.pgn file was examined using the Notepad++ editor on Windows: occasionally characters would show up as white hexadecimal text on black background. This indicated some kind of encoding error.
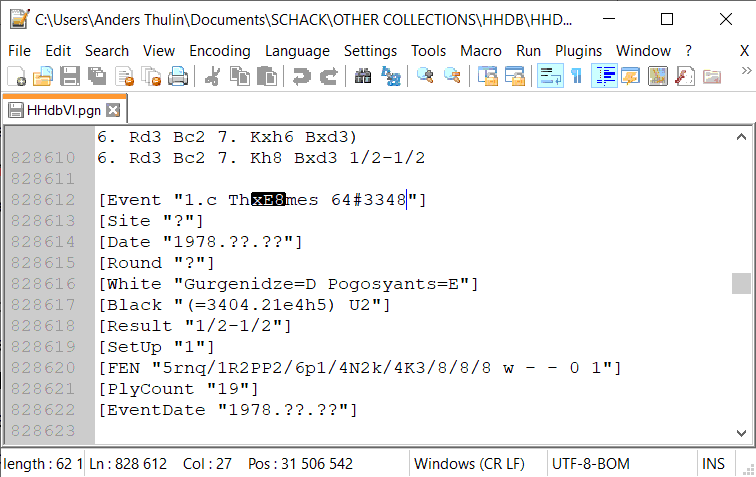
The marker is visible in line 828612. This corresponds to game 42905 in Fritz Database view or byte offset 0x1E0C056 in the file, where a PGN record with the following tag pair section begins:
[Event "1.c Thèmes 64#3348"]
[Site "?"]
[Date "1978.??.??"]
[Round "?"]
[White "Gurgenidze=D Pogosyants=E"]
[Black "(=3404.21e4h5) U2"]
[Result "1/2-1/2"]
[SetUp "1"]
[FEN "5rnq/1R2PP2/6p1/4N2k/4K3/8/8/8 w - - 0 1"]
[PlyCount "19"]
[EventDate "1978.??.??"]
The issue is in the first line, which refers to Thèmes 64, the title of a periodical for chess problems and studies. There’s little doubt that there should be an è in the title, yet Notepad++ displayed a white xE8 on black background in its place.
In an UTF-8 encoded file, an ‘è’ would be encoded as two bytes: 0xC3 0xA8. In this file it is encoded as 0xE8, which is the code used by ISO 8859-1.
A closer look revealed 2341 instances of 0xE8 in the file, which means 2341 places where correct UTF-8 decoding would either run into an illegal encoding, or decode to a bad character. A test conversion showed that the conversion tool simply dropped all bad codes: this would lead to substantial database incorrectness – in the cited example, the reference was to Thmes 64, that is without the è.
An analysis of bytes with values in the range 0xA0-0xFF came up with the following bytes, not including the BOM:
| code | count | ISO8859-1 | occurs in |
|---|---|---|---|
| 0xDF | 1 | ß | Gießener |
| 0xE0 | 21 | à | Ceskà or sottilità |
| 0xE2 | 1 | â | Frytslân |
| 0xE4 | 1 | ä | Niedersächsische |
| 0xE7 | 46 | ç | Française |
| 0xE8 | 2341 | è | Thèmes 64 [all instances have not been checked!] |
| 0xEA | 1 | ê | Les Pions sans Gêne |
| 0xEE | 4 | î | Chaînon |
| 0xF8 | 7 | ø | Vanføres [almost all] |
| 0xFC | 1 | ü | Lüneburger |
In all examined cases, ISO 8859-1 characters appeared to be used, instead of the expected UTF-8 encoding. This suggests that the file really is a correctly encoded PGN file, but that an UTF-8 BOM for some reason has been added at the beginning.
Issue 2: CRLF as line terminators
PGN also requires that export format or archive format files use LF as line terminators. CRLF is not clearly permitted, even if there are some kind of situations where it may be allowed, but they are not well specified and so will probably depend on how the implementer interprets the standard; in this case we will be as strict as possible, and insist on LF only.
Fix: Convert to Real ISO 8859-1 & no CRLF
In a Unix/Linux environment, execute the following commands (shown preceded by $ below).
$ file HHdbVI.pgn
HHdbVI.pgn: UTF-8 Unicode (with BOM) text, with CRLF line terminators
$ dos2unix -r < HHdbVI.pgn > HHdbVI-iso8859.pgn
$ file HHdbVI-is08859.pgn
HHdbVI-iso8859.pgn: ASCII text
(Make sure you have a backup of the original file!)
The dos2unix application removes the BOM as well as replaces all CRLF with LF. To double-check that it has worked:
$ diff --strip-trailing-cr HHdbVI.pgn HHdbVI-is08859.pgn
1c1
< [Event "13th UAPA internet ty#13"]
---
> [Event "13th UAPA internet ty#13"]
The output shows that the only difference is in the first line of the files (1c1). This is where the removed BOM was located. The –strip-trailing-cr option makes diff ignore differences involving CR: if you do not include that, every line will be reported as different.
If you get other differences, there is something else going on, and additional investigation is probably called for.
In other environments (e.g. Windows) other tools may be required. The hex editor HxD can both delete the BOM (the first three bytes of the files) as well as replace all CRLF with LF, for example.
Additional issues
There are still some isses that may cause problems.
PGN requires movetext lines to contain fewer than 80 printing characters (see section 8.2.1 in the PGN Standard). While this seems to be a silly restriction on a data exchange file format, it is nevertheless there, and some PGN software may enforce it.
In Unix, it is possible to identify lines that break this requirement as follows:
% awk 'length>79' HHdbVI-iso8859-1-LF.pgn
The output mainly contains movetext lines, but it also includes some tag pair lines. These are not clearly subject to the movetext line length restriction (see section 4.3), but poorly written software may nevertheless implement one. If that should be the case, they need to be made shorter. I’ve only identified eight such lines, so this is possible to do by hand with a good text editor (such as Notepad++). The lines I’ve found are these:
[Event "1.hm Novo-Voronezh Nuclear Power Station-40 AT Shakhmatnaya Kompozitsia"]
[Event "1/2.p Novo-Voronezh Nuclear Power Station-40 AT Shakhmatnaya Kompozitsia"]
[Event "1/2.p Novo-Voronezh Nuclear Power Station-40 AT Shakhmatnaya Kompozitsia"]
[Event "2.hm Novo-Voronezh Nuclear Power Station-40 AT Shakhmatnaya Kompozitsia"]
[Event "3.hm Novo-Voronezh Nuclear Power Station-40 AT Shakhmatnaya Kompozitsia"]
[Event "3.p Novo-Voronezh Nuclear Power Station-40 AT Shakhmatnaya Kompozitsia"]
[Event "4.p Novo-Voronezh Nuclear Power Station-40 AT Shakhmatnaya Kompozitsia"]
[Event "5.p Novo-Voronezh Nuclear Power Station-40 AT Shakhmatnaya Kompozitsia"]
However, well-written software should not have any problems here.
The movetext lines is another matter, as there is an explicit requirement in the PGN standard that they may not contain more than 79 printing characters.
There is a possible fix, but as I haven’t tested it with software that I know complains about long movetext lines, I don’t want to claim that it works.
If the only remaining line-length issue that remains concerns length of movetext data lines (see discussion above), it may be possible to use the unix command ‘fold’ using ‘-c 79’ for max line length and ‘-s’ to force line breaks only at spaces.
However, if the long tag pairs mentioned above remain unchanged, these will also be folded, and that will almost certainly upset also normal PGN software.